Learning robust perceptive locomotion for quadrupedal robots in the wild
2025-03-01
Results
Fast and robust locomotion in the wild
빠르고 견고한 이동
- 다양한 지형에서 강력한 성능
- 알프스, 숲, 지하, 도시 등에서 안정적인 보행
- 낙하 없이 부드럽고 빠른 이동 유지
- 알프스, 숲, 지하, 도시 등에서 안정적인 보행
- Exteroception을 활용한 지형 적응
- 지형을 예측하여 장애물 및 계단에서도 효과적인 보행
- 자연 및 도시 환경에서도 높은 적응력
- 가파른 경사, 미끄러운 표면, 풀, 눈 등 도전적인 조건 극복
- 기존 로봇(Spot)과 달리 특별한 설정 없이 자유롭게 계단 이동
- 가파른 경사, 미끄러운 표면, 풀, 눈 등 도전적인 조건 극복
- 눈 덮인 계단에서도 신뢰성 유지
- 센서 오류 및 발 미끄러짐에도 실패 없이 안정적인 작동

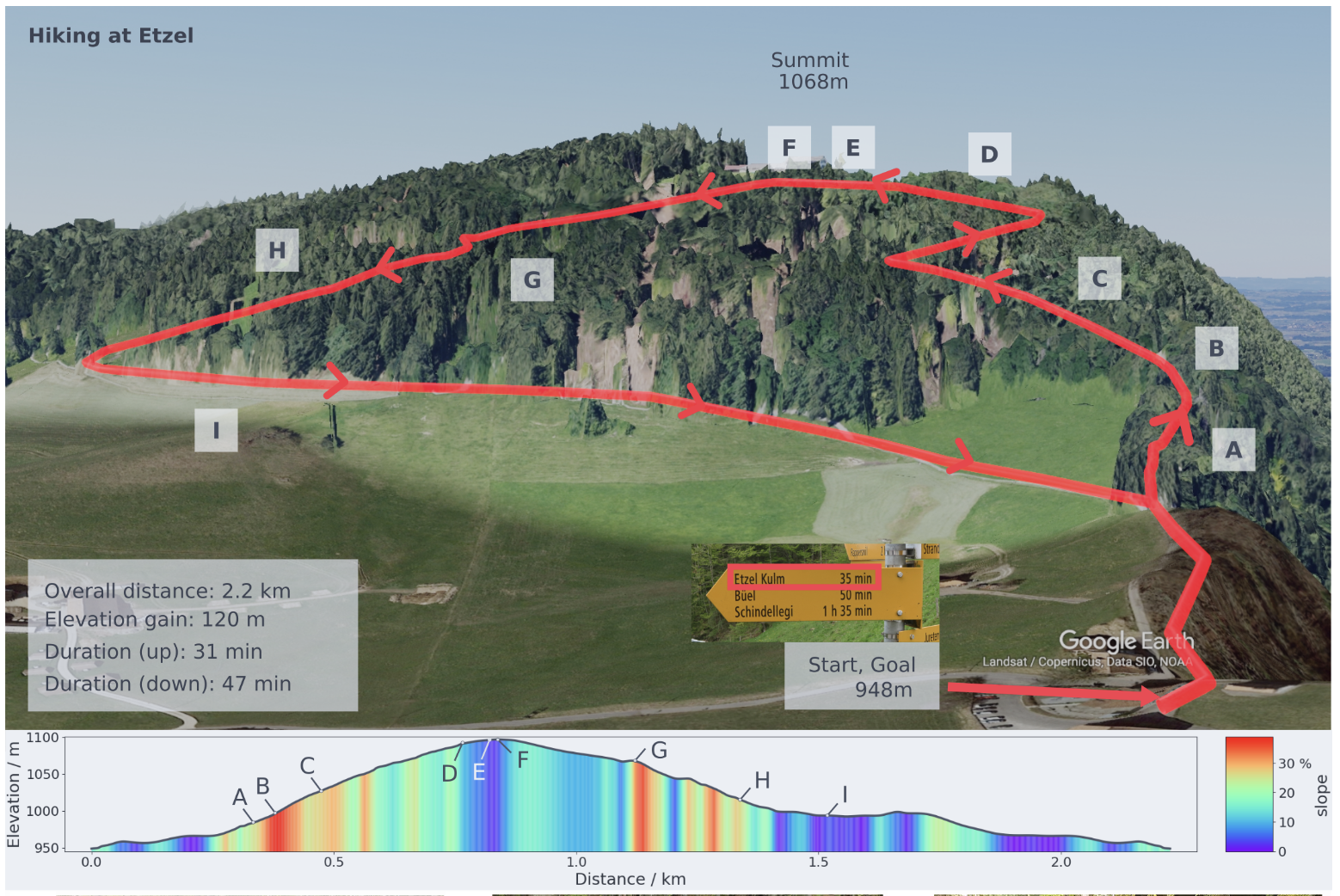
A hike in the Alps
알프스 하이킹
- 하이킹 실험 개요
- 스위스 에첼 산에서 ANYmal의 강건성 테스트
- 2.2km 거리, 120m 고도 상승 포함
- 스위스 에첼 산에서 ANYmal의 강건성 테스트
- 경로의 도전 요소
- 가파른 경사(최대 38%), 높은 단계, 바위 표면, 미끄러운 지면, 나무 뿌리 장애물 존재
- 식생으로 인한 height map 오류 발생
- 가파른 경사(최대 38%), 높은 단계, 바위 표면, 미끄러운 지면, 나무 뿌리 장애물 존재
- 실험 결과
- 분리된 신발 수리 및 배터리 교체 외에는 실패 없이 완주
- 정상 도착: 31분 (인간 예상 시간 35분보다 빠름)
- 전체 경로 완료: 78분 (하이킹 플래너 예상 76분과 유사)
- 분리된 신발 수리 및 배터리 교체 외에는 실패 없이 완주
- 로봇의 성능
- 인간의 도움 없이 자율적으로 이동
- 단 한 번의 낙하 없이 하이킹 성공
- 인간의 도움 없이 자율적으로 이동
Evaluating the contribution of exteroception
exteroception이 로봇의 이동 성능에 미치는 영향을 정량적으로 평가
- Exteroception의 한계
- 센서 감지 오류: 반사성/반투명 표면에서 깊이 추정 실패 (예: 금속 바닥, 눈)
- 2.5D 고도 맵의 제약: 나뭇가지·낮은 천장을 높은 장애물로 오인, 부드러운 식생·깊은 눈에서 부정확한 정보 제공
- 미끄럽거나 변형 가능한 표면: 오도메트리 드리프트 유발, 맵 구축 오류 발생
- 시점 제한: 로봇 뒤쪽 영역이 맵에 포함되지 않아 오르막에서 문제 발생
- 센서 감지 오류: 반사성/반투명 표면에서 깊이 추정 실패 (예: 금속 바닥, 눈)

- Controller의 적응성
- Exteroception의 신뢰성을 평가하는 신뢰 상태 추정기 활용
- 감각 정보가 신뢰할 수 없을 경우, Proprioception(고유감각) 운동으로 자연스럽게 전환
- Exteroception을 사용할 수 있을 때는 빠른 예측 운동 수행, 그렇지 않을 때는 안정적인 자체 감각 제어 유지
- Proprioception만 사용하는 Baseline과 비교
- Exteroception의 신뢰성을 평가하는 신뢰 상태 추정기 활용
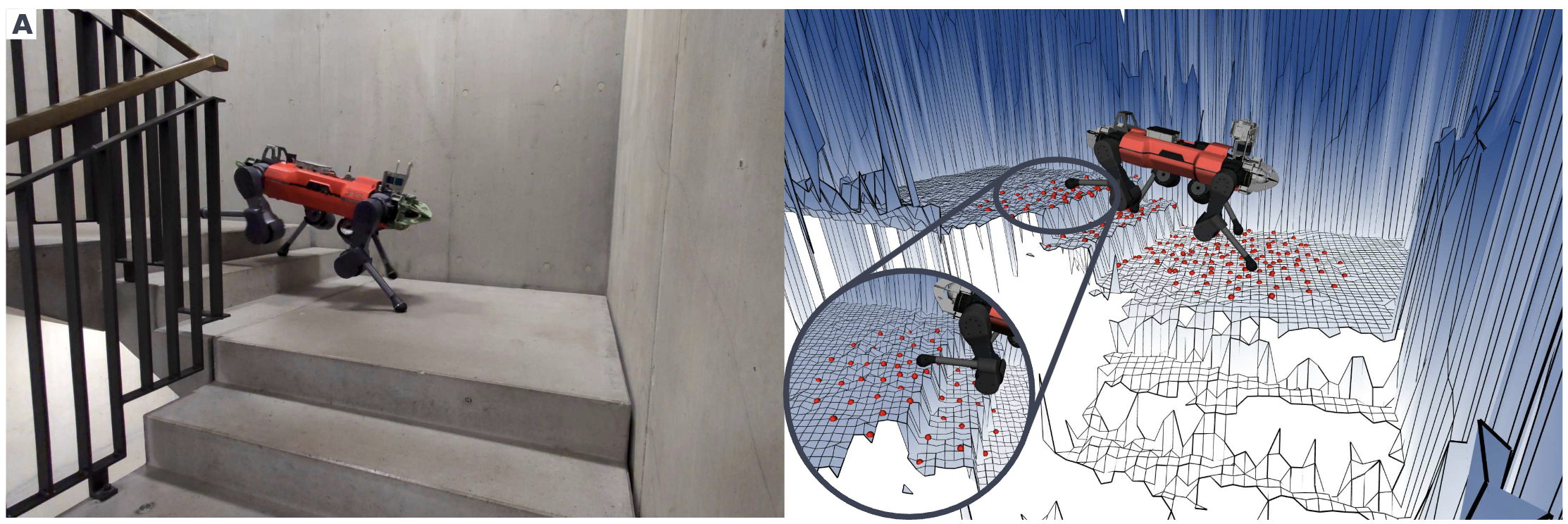
- 계단 극복 실험
- 12cm~36.5cm 높이의 나무 계단을 극복하는 성공률 비교
- 최대 30.5cm까지 신뢰성 있게 극복
- Baseline은 20cm부터 성공률 급감, 뒷다리가 종종 올라가지 못함
- Baseline은 20cm부터 성공률 급감, 뒷다리가 종종 올라가지 못함
- 32cm 이상에서는 물리적 한계를 인식하고 무리한 시도를 피함
- 12cm~36.5cm 높이의 나무 계단을 극복하는 성공률 비교
- 장애물 코스 실험
- 로봇이 경사진 플랫폼, 높이 있는 플랫폼, 계단, 블록 더미 등을 통과하도록 설정
- 외부 감각을 활용하여 사전 조정 후 부드럽게 통과
- Baseline은 장애물에 걸려 진행 불가, 실험 지속을 위해 수동 개입 필요
- 로봇이 경사진 플랫폼, 높이 있는 플랫폼, 계단, 블록 더미 등을 통과하도록 설정
- 최대 이동 속도 비교
- 평지 속도: 1.2m/s (Baseline 0.6m/s)
- 장애물 위 속도: 속도 저하 없이 통과 (Baseline는 막힘)
- 회전 속도: 3 rad/s (Baseline 0.6 rad/s (5배 차이))
Evaluating robustness with belief state visualization
belief state 시각화를 통한 robustness 평가
로봇이 Proprioception과 Exteroception을 어떻게 통합하는지 분석
Exteroception이 불완전하거나 오류를 포함할 때의 반응 평가
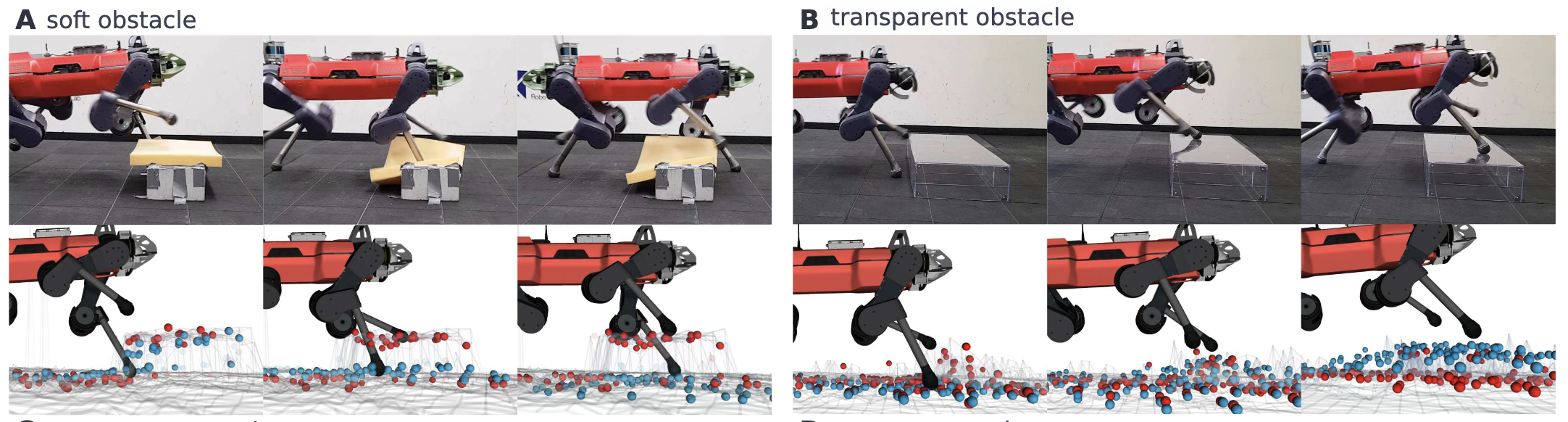
모호한 Exteroception 실험
- 불투명 폼 장애물: 센서가 단단한 장애물로 오인 → 로봇이 발을 디뎠으나 불안정
- 접촉 후 빠르게 높이 추정을 수정하여 적응
- 접촉 후 빠르게 높이 추정을 수정하여 적응
- 투명 장애물(아크릴 블록): 센서가 인식하지 못함 → 로봇이 접촉 후 보행 방식 조정
- 불투명 폼 장애물: 센서가 단단한 장애물로 오인 → 로봇이 발을 디뎠으나 불안정
- Exteroception 완전 차단 실험
- 센서를 덮어 Exteroception을 무효화한 상태에서 계단 오르내리기
- 정상 센서 상태: 매끄럽게 계단을 통과
- 센서 차단 상태: 첫 번째 계단에서 예상치 못한 접촉 발생 → 지형 추정을 수정하며 적응
- 센서를 덮어 Exteroception을 무효화한 상태에서 계단 오르내리기

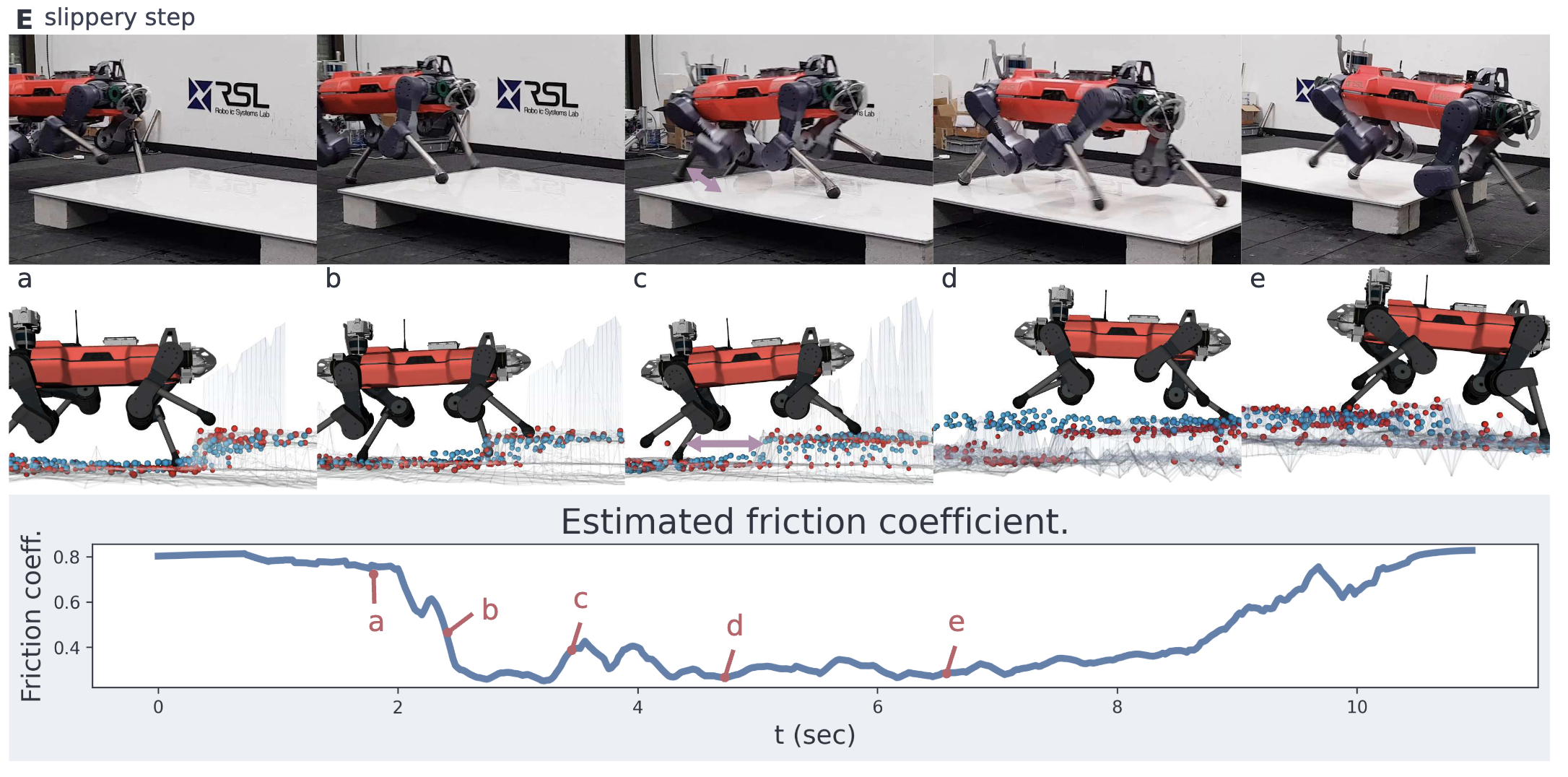
- 미끄러운 표면에서의 반응 실험
- 발이 미끄러짐을 감지한 후 보행 속도를 조정하여 균형 유지
- 미끄러짐으로 인해 고도 맵이 불안정해졌을 때, Exteroception을 배제하고 Proprioception으로 보행 유지
- 발이 미끄러짐을 감지한 후 보행 속도를 조정하여 균형 유지
결론
- 로봇은 Exteroception을 신뢰하지만, 오류를 감지하면 즉각 수정하여 적응
- Exteroception이 무효화되면 Proprioception을 활용하여 안정적으로 이동
- 환경 변화에 따라 보행 방식을 유연하게 조정하는 능력 입증
Method
POMDP
- \(o_t \neq s_t\)
- 과거 관측 데이터 \(\left\{o_0, \cdots, o_t\right\}\) 를 이용해 신뢰 상태(belif state) \(b_t\)를 구성하여 전체 상태를 추정
- Privileged Learning 활용
- Teacher Policy: Privileged Information를 활용해 먼저 학습
- Student Policy: 지도 학습을 통해 Teacher 정책을 압축하여 학습
RaiSim / ANYmal-C
Terrain
- height map으로 모델링 - 다양한 경사 및 계단 지형을 포함하여 네 가지 계단 유형 모델링 - 표준(Standard), 개방형(Open), 단턱형(Ledged), 무작위(Random) 계단 - 계단을 박스 형태로 구성하여 훈련 - height map 기반 계단의 문제점 - height map으로 모델링한 계단의 단차(riser)는 완전히 수직이 아님 - 정책이 시뮬레이션에서 이 비수직성을 악용하는 현상 발견 - 이로 인해 현실(world)에서의 성능 저하(sim-to-real transfer 문제) 발생

Domain Randomization
- 로봇의 몸체 및 다리 질량 무작위화 - 초기 관절 위치 및 속도, 초기 몸체 자세 및 속도 무작위화 - 외부 힘(Force) 및 토크(Torque) 적용 - 발 마찰 계수를 낮춰 미끄러짐(Slippage) 유도Termination
- 로봇이 비정상적인 상태(Undesirable State) 에 도달하면 에피소드 종료 후 재시작 - 몸체가 지면과 충돌 - 과도한 몸체 기울기 발생 - 관절 액추에이터의 토크 한계 초과
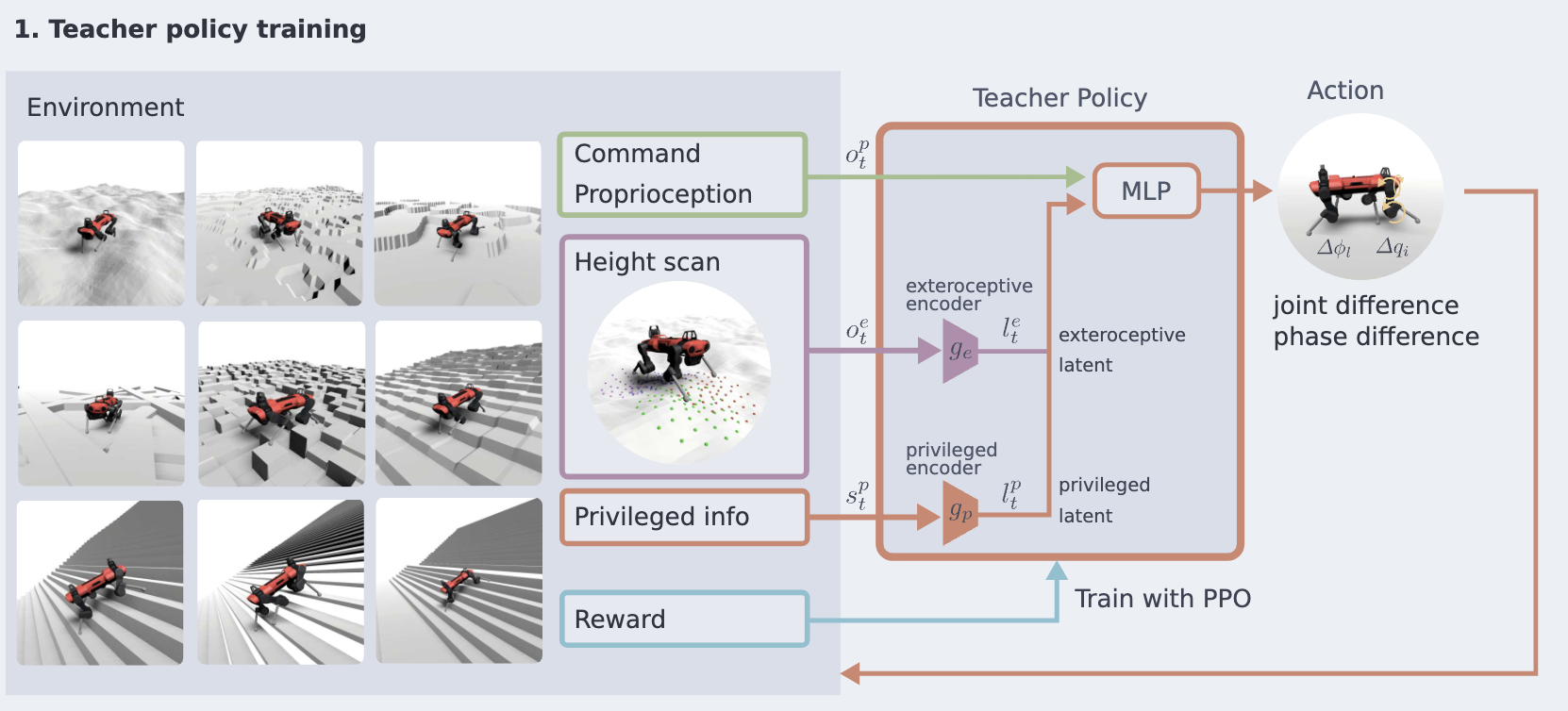
- Privileged Information를 활용하여 최적의 reference 정책 학습
- 랜덤 지형에서 원하는 속도 명령을 따르는 정책 학습
- \(\mathbf{v}_{\text {des }} \in \mathbb{R}^3=\left(v_x, v_y, \omega\right)\)
- PPO 사용
- 가우시안 policy: \(a_t \sim \text{N}\left(\pi_\theta\left(o_t=s_t\right), \sigma I\right)\)
Observation / Action
- \(o_t^{\text {teacher }}=\left(o_t^p, o_t^e, s_t^p\right)\)
- \(o_t^p\): 고유 감각(Proprioceptive)
- 몸체 속도, 자세, 관절 위치 및 속도 이력
- 행동 이력, 각 다리의 보행 위상(phase)
- \(o_t^e\): 외부 감각(Exteroceptive)
- 각 발 주변에서 5개의 반경(radii) 을 기준으로 샘플링한 높이 정보
- \(s_t^p\): Privilaged 상태
- 접촉 상태, 접촉 힘, 접촉 법선(normal), 마찰 계수
- 허벅지(thigh) 및 정강이(shank) 접촉 여부
- 로봇 몸체에 작용하는 외력 및 토크, 보행 스윙(swing) 지속 시간
- \(o_t^p\): 고유 감각(Proprioceptive)
- CPG(Central Pattern Generator) 기반 action 설계
- 각 다리 \(\text{L}={1,2,3,4}\) 가 보행 위상 변수 \(\phi_L\) 를 유지
- 보행 위상을 기반으로 발끝(foot tip)의 nominal trajectory 정의
- desired joint position \(q_i\left(\phi_L\right)\) 계산: 역기구학 사용
- policy output
- 위상 변화량 \(\Delta \phi_L\)
- 관절 목표 잔차 \(\Delta q_i\) (기본 궤적에서의 보정값)
Architecture
- MLP 기반
- 입력 데이터를 간결한 표현으로 압축 → 효율적이고 안정적인 학습 가능
- Student Policy가 일부 Teacher Policy 구조를 재사용 가능
- 세 가지 주요 구성 요소 포함
- 입력 데이터를 간결한 표현으로 압축 → 효율적이고 안정적인 학습 가능
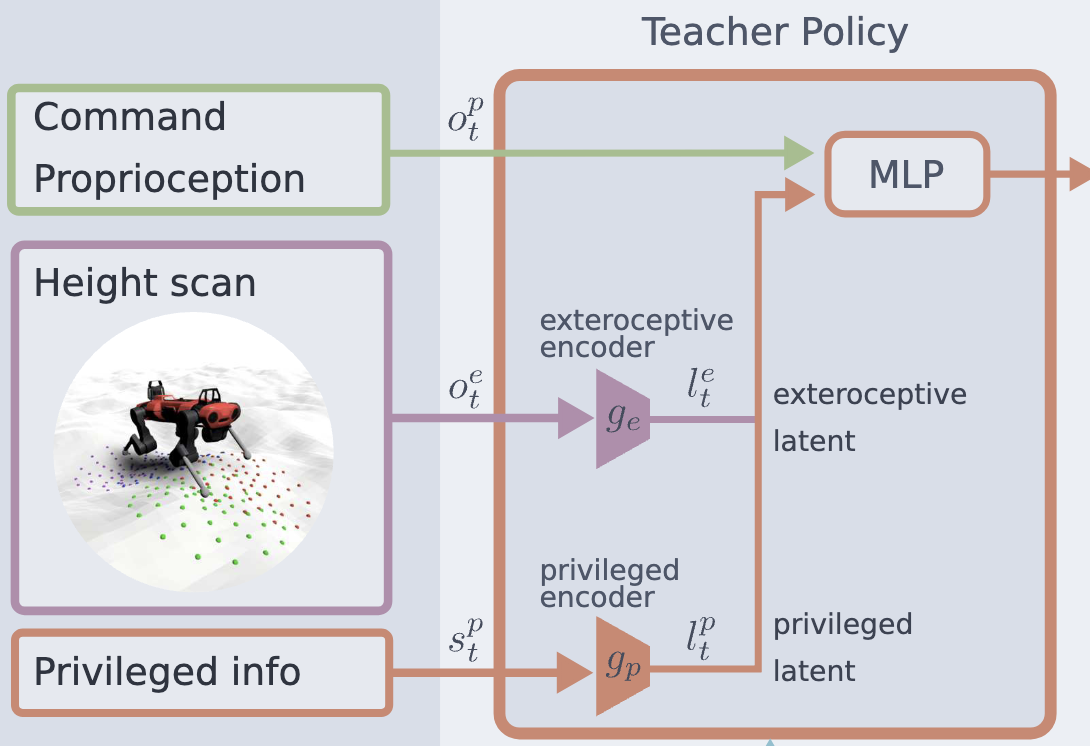
- exteroceptive encoder \(g_e\)
- 입력: \(o_t^e\) (외부 감각 정보)
- 출력: latent representation \(l_t^e\)
- 입력: \(o_t^e\) (외부 감각 정보)
\[\begin{equation} l_t^e=g_e\left(o_t^e\right) \end{equation}\]
- privileged encoder \(g_p\)
- 입력: \(s^p_t\) (특권 상태 정보)
- 출력: latent representation \(l^{priv}_t\)
- 입력: \(s^p_t\) (특권 상태 정보)
\[\begin{equation} l_t^{p r i v}=g_p\left(s_t^p\right) \end{equation}\]
- main network
- 위 인코더에서 생성된 latent representation을 활용하여 정책 학습
Reward
속도 명령 준수 보상 \(r_{\text{command}}\)
로봇이 원하는 속도 명령을 따르도록 유도
yaw 회전 속도에 대해서도 동일한 보상 적용
\(r_{\text {command }}= \begin{cases}1.0, & \text { if } \boldsymbol{v}_{\text {des }} \cdot \boldsymbol{v}>\left|\boldsymbol{v}_{\text {des }}\right| \\ \exp \left(-\left(\boldsymbol{v}_{\text {des }} \cdot \boldsymbol{v}-\left|\boldsymbol{v}_{\text {des }}\right|\right)^2\right), & \text { otherwise }\end{cases}\)
변수 설명:
- \(v_{\text{des}} \in \mathbb{R}^2\): 목표 수평 속도 (바디 프레임 기준)
- \(v \in \mathbb{R}^2\): 현재 수평 속도 (바디 프레임 기준)
- \(v_{\text{des}} \in \mathbb{R}^2\): 목표 수평 속도 (바디 프레임 기준)
페널티 항 (제약 위반 방지)
- 목표와 직교하는 속도 → 목표 방향에서 벗어나지 않도록 페널티 부여
- 몸체의 롤, 피치, 요 속도 → 불필요한 회전 방지
- 체형 안정성 관련 페널티
- 몸체 자세 (Body Orientation) → 비정상적인 자세 방지
- 관절 토크, 속도, 가속도 → 과격한 동작 방지
- 발 미끄러짐 (Foot Slippage) 및 정강이/무릎 충돌 (Shank & Knee Collision) 방지
- 몸체 자세 (Body Orientation) → 비정상적인 자세 방지
- 목표와 직교하는 속도 → 목표 방향에서 벗어나지 않도록 페널티 부여
보상 튜닝 과정
- 시뮬레이션에서 정책의 행동을 직접 관찰하여 보상 항 조정
- 이동 성능뿐만 아니라 보행의 부드러움(Smoothness) 도 평가
- 최종 보상 식: \(r=0.75\left(r_{l v}+r_{a v}+r_{l v o}\right)+r_b+\) \(0.003 r_{f c}+0.1 r_{c o}+0.001 r_j+0.08 r_{j c}+0.003 r_s+1.0 \cdot 10^{-6} r_\tau+\) \(0.003 r_{\text {slip }}\)
커리큘럼 학습
- 난이도를 점진적으로 증가시키는 두 가지 커리큘럼을 적용
- 지형 난이도 커리큘럼 (Terrain Curriculum)
- 적응형 방법(Adaptive Method) 활용
- 파티클 필터(Particle Filter) 를 사용하여 지형 난이도를 조정
- 정책 학습 중 항상 도전적이지만 해결 가능한 수준의 지형을 유지
- 적응형 방법(Adaptive Method) 활용
- 보상 및 외란 조정 커리큘럼
- Domain Randomization 및 특정 보상 항목(관절 속도, 가속도, 자세, 미끄러짐, 정강이/허벅지 접촉 등)의 크기를 점진적으로 증가
- 적용 방식: 로지스틱 함수(Logistic Function) 기반 변화율 적용
- \(c_{k+1}=\left(c_k\right)^d\)
- \(c_k\): 현재 커리큘럼 요소(난이도) 값
- \(d\): 수렴 속도 \(0 < d < 1\)
- \(c_k\) 값이 점진적으로 증가하며 최대 1로 수렴
- \(c_{k+1}=\left(c_k\right)^d\)
- Domain Randomization 및 특정 보상 항목(관절 속도, 가속도, 자세, 미끄러짐, 정강이/허벅지 접촉 등)의 크기를 점진적으로 증가
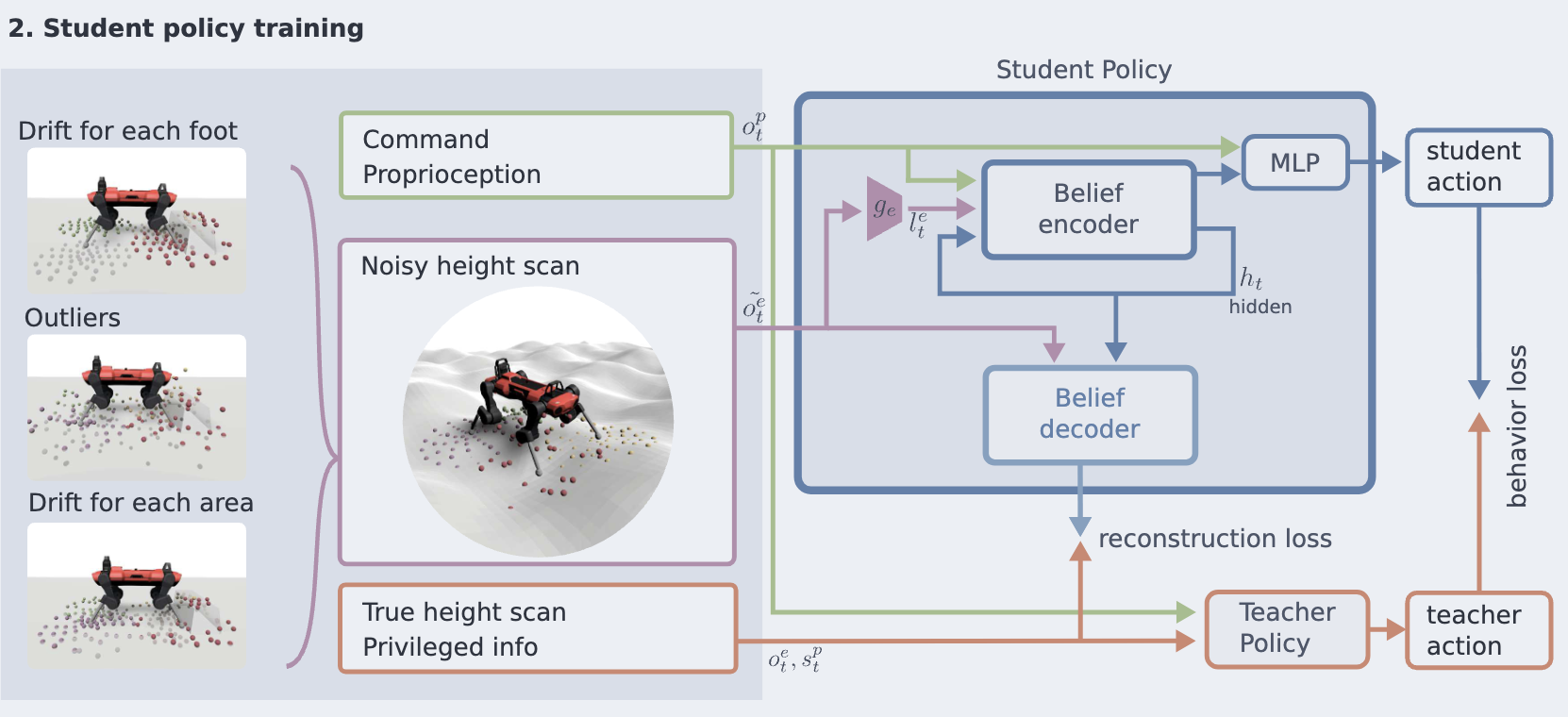
- Distillation Teacher → Student Policy
- Teacher: Privileged Information를 활용하여 학습됨
- Student: 실제 로봇에서 사용할 수 있는 정보만 접근 가능해야 함
- Teacher: Privileged Information를 활용하여 학습됨
- Student Policy은 Privileged Information 없이도 Teacher 정책의 성능을 유지하면서 강건하게 동작하도록 학습
- Noise 적용 + Belief State Encoder 를 통해 POMDP 해결
학습 과정
학습 과정은 동일하게 유지, 하지만 Student 정책의 높이 샘플 관측에 추가적인 Noise 적용
- 실제 환경에서 흔히 발생하는 외부 감각 오류를 시뮬레이션
- 예: 센서 오작동, 깊이 측정 오류, 반사율이 높은 표면에서의 감지 실패 등
\[ o^{\text{student}}_t = (o^p_t, n(o^e_t)) \]
- \(o^p_t\): 고유 감각(Proprioceptive) 관측 정보
- \(o^e_t\): 외부 감각(Exteroceptive) 관측 정보
- \(n(o^e_t)\): Noise 모델을 적용한 외부 감각 데이터
Belief State Estimation
- 순차적 정보(Squential Information)를 활용하여 보정
- 외부 감각 + 고유 감각의 시퀀스를 통합하여 Belief State 추정
- Recurrent Belief State Encoder 적용
- RNN, GRU, 또는 LSTM 같은 순환 구조를 사용하여 시간적 상관관계 유지
Architecture
Recurrent Belief State Encoder + MLP
- MLP 구조 유지 및 가중치 초기화
- Teacher Policy과 동일한 MLP 구조 사용. Teacher Policy의 가중치를 재사용하여 학습 속도 향상
- hidden state \(h_t\) 를 유지하여 시간적 정보(Time Dependency) 유지
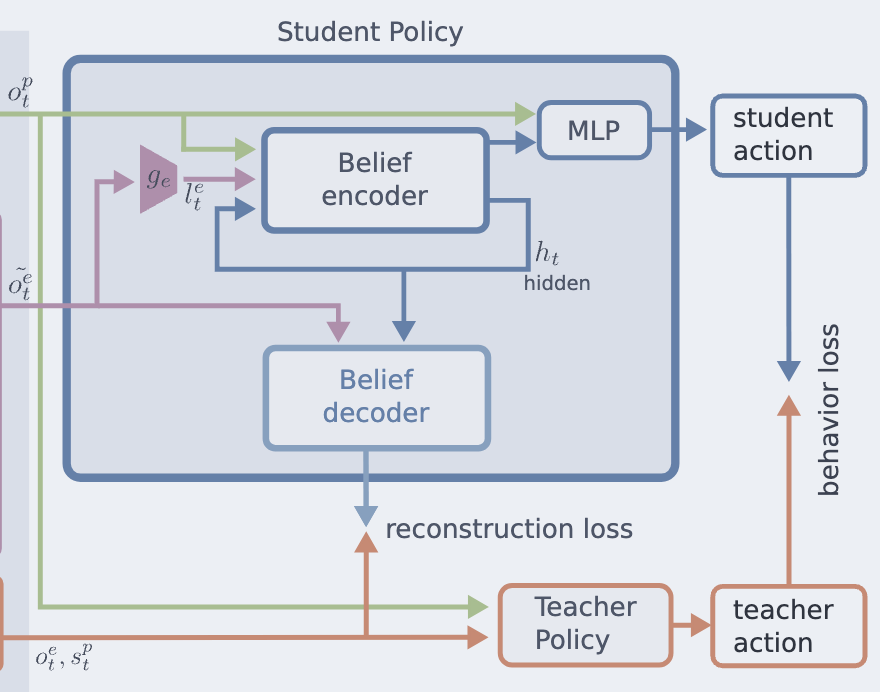
- 입력:
- Student Policy 관측 \(o^{\text{student}}_t\)
- hidden state \(h_t\)
- Student Policy 관측 \(o^{\text{student}}_t\)
- Belief State 벡터 \(b_t\) 생성:
- Belief State Encoder를 통해 잠재 벡터 \(b_t\) 출력
- \(b_t\) 가 Teacher Policy의 특징 벡터 \((l^e_t, l^{priv}_t)\) 와 유사하도록 학습
- Belief State Encoder를 통해 잠재 벡터 \(b_t\) 출력
- 최종 정책 출력:
- \(b_t\) 와 고유 감각 \(o^p_t\) 를 MLP에 입력하여 최종 Action 출력
학습 방식
- Student Policy은 지도 학습 방식으로 학습되며, 2 가지 손실 함수를 최소화함
- 지도 학습(Behavior Cloning + Reconstruction Loss) 방식으로 빠르게 학습 가능
- Behavior Cloning Loss
- 동일한 상태와 속도 명령이 주어졌을 때
- Student Policy 행동과 Teacher Policy 행동 간의 차이 최소화
- 손실 함수:
\[ L_{\text{BC}} = || a_{\text{student}} - a_{\text{teacher}} ||^2 \]
- 동일한 상태와 속도 명령이 주어졌을 때
- Reconstruction Loss
- 신뢰 상태 \(b_t\) 가 Teacher Policy의 특징 벡터 와 유사하도록 학습
- 잡음이 없는 높이 샘플 및 특권 정보 \((o^e_t, s^p_t)\) 와의 차이 최소화
- 손실 함수:
\[ L_{\text{Recon}} = || b_t - (l^e_t, l^{priv}_t) ||^2 \]
- 신뢰 상태 \(b_t\) 가 Teacher Policy의 특징 벡터 와 유사하도록 학습
- Rollout for Robustness
- Student Policy을 직접 롤아웃(Rollout) 하면서 데이터 생성
- 실제 배치 환경에서도 강건한 행동을 하도록 학습 강화
- Student Policy을 직접 롤아웃(Rollout) 하면서 데이터 생성
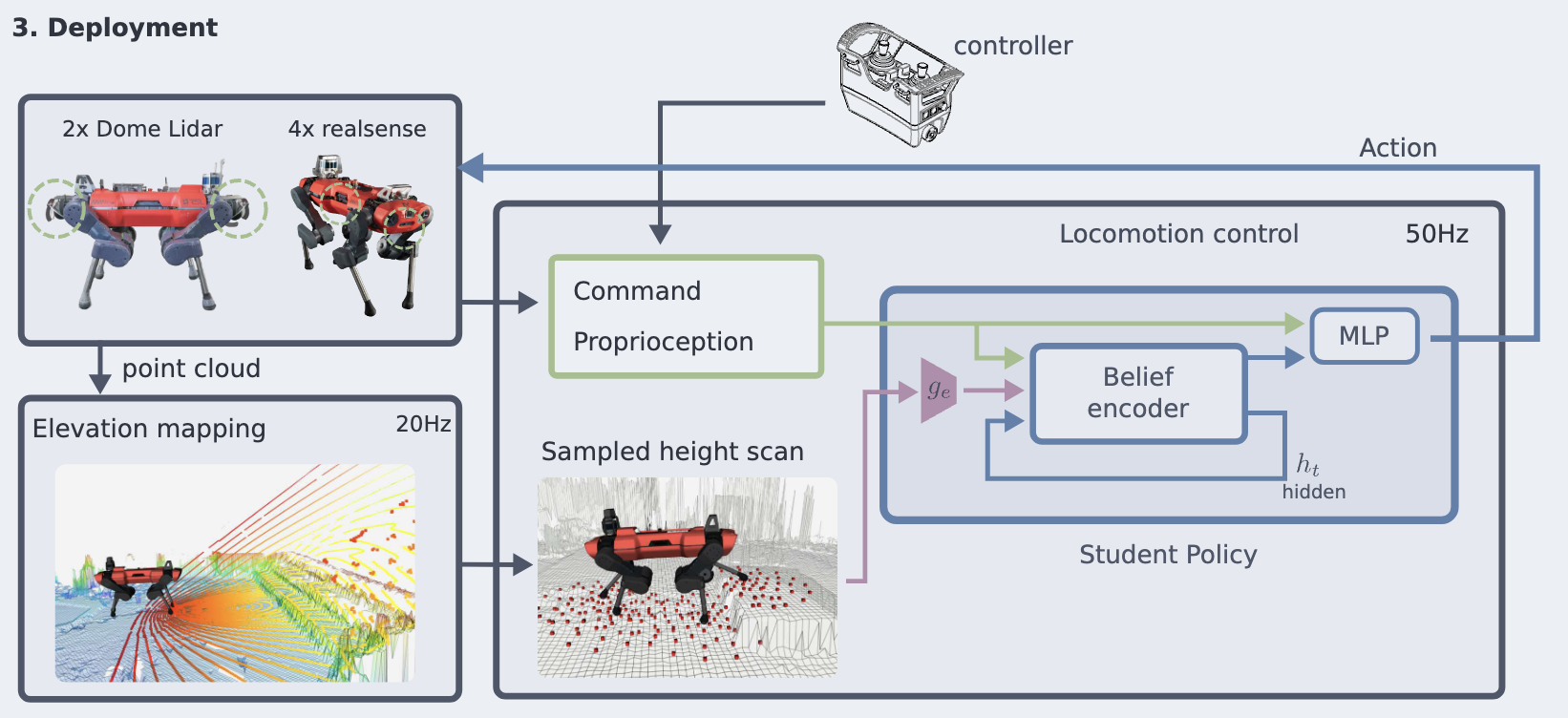
ANYmal-C 로봇에서 컨트롤러 배포 및 센서 구성
- 두 가지 센서 구성 사용
- LiDAR 기반 구성: Robosense Bpearl 돔 LiDAR 2개 사용
- Depth 카메라 기반 구성: Intel RealSense D435 Depth 카메라 4개 사용
- Zero-Shot 모델 배포 및 실행: 세부 조정 없이 즉시 실행 가능
- height map 구축
- 로봇 중심의 2.5D Height Map 구축
- 포인트 클라우드(센서 데이터) 활용, 20Hz 주기로 업데이트
- 정책은 50Hz로 실행, 최신 height map에서 높이 샘플링
- 맵 정보가 부족한 영역은 무작위 값으로 보완
- 로봇 중심의 2.5D Height Map 구축
- 빠른 지형 매핑 시스템 개발: 빠른 보행 속도에 맞춰 실시간 환경 분석 가능
- GPU 병렬 처리 기반 고도 매핑 파이프라인 구축
- 칼만 필터 기반 맵 업데이트
- 드리프트 보정 및 레이 캐스팅(ray-casting) 적용
Height sample randomization
Student Policy 방법론 더 자세히
👉 핵심 아이디어
- 실제 환경에서 발생할 수 있는 다양한 센서 오류 및 맵 품질 저하를 학습 시뮬레이션
- Noise 적용 방식을 세분화하여 다양한 조건에서 정책이 강건하게 작동하도록 유도
- 지형 특성 변화도 반영하여 현실적인 지형 적응 능력 강화- Noise 모델 적용
- Noise 모델 \(n(\tilde{o}^e_t | o^e_t, z)\), \(z \in \mathbb{R}^{8 \times 4}\) 사용
- 높이 샘플에 두 가지 유형의 측정 Noise 추가
- Scan Point를 수평으로 이동(Shift)
- 높이 값에 교란 추가(Height Disturbance)
- Scan Point를 수평으로 이동(Shift)
- Noise 값은 가우시안 분포 에서 샘플링되며, Noise 매개변수 \(z\) 가 분산을 결정
- Noise 매개변수 벡터 \(z\) 는 커리큘럼 학습의 일부
- 훈련 기간이 진행됨에 따라 Noise 강도를 선형적으로 증가
- Noise 매개변수 벡터 \(z\) 는 커리큘럼 학습의 일부
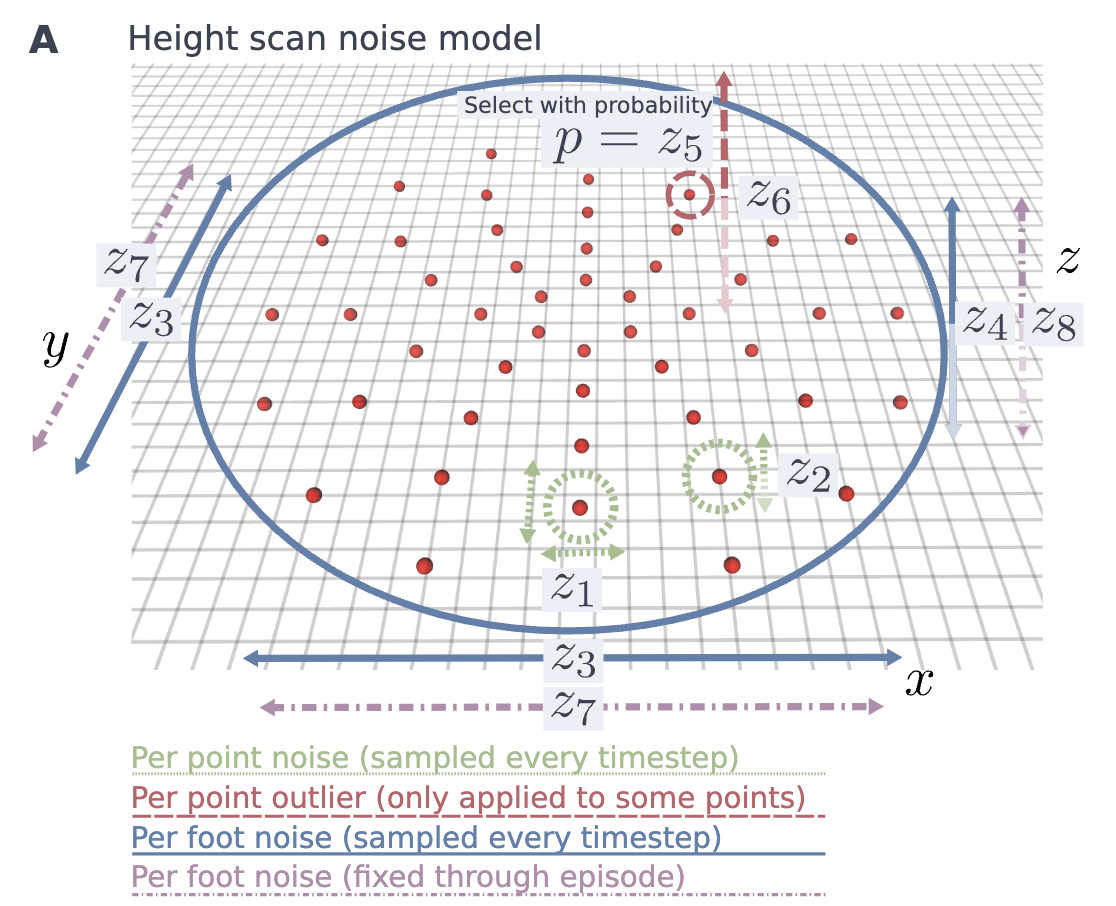
- Noise는 3가지 다른 범위 에서 적용
- Per-Scan-Point → 각 스캔 포인트마다 매 시간 단계마다 재샘플링
- Per-Foot → 각 다리(발)별로 매 시간 단계마다 재샘플링
- Per-Episode → 모든 스캔 포인트에 대해 일정한 Noise 유지
매핑 오류 시뮬레이션
- 맵 품질 변화 및 오류 원인 시뮬레이션
- 3가지 매핑 조건 정의 (훈련 에피소드에서 60%, 30%, 10% 확률로 선택)
- 정상적인 운영 상태 → 양호한 맵 품질, 표준적인 Noise 적용
- 지도 오프셋 발생 → 자세 추정 드리프트 또는 변형 가능한 지형(예: 진흙, 눈)으로 인해 큰 오프셋 추가
- 매핑 실패 시뮬레이션 → 폐색(occlusion) 또는 센서 오류로 인해 각 스캔 포인트에 큰 Noise 추가
- 정상적인 운영 상태 → 양호한 맵 품질, 표준적인 Noise 적용
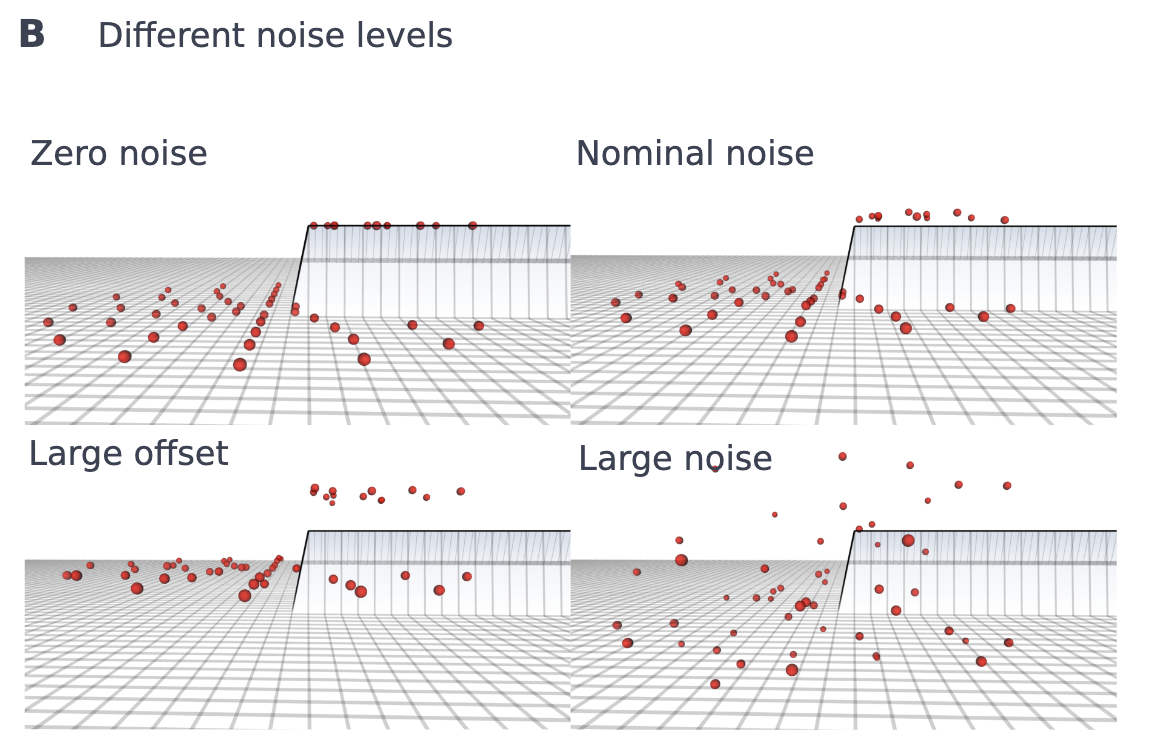
지형 변화 시뮬레이션
- 훈련 지형을 셀(Cell) 단위로 나누고, 특정 셀의 height map에 추가 오프셋 적용
- 서로 다른 지형 특성 간의 전환 시뮬레이션 (예: 식생, 깊은 눈 등)
Belief state encoder
Student Policy 방법론 더 자세히
👉 핵심 아이디어
- 고유 감각(Proprioception)과 외부 감각(Exteroception) 정보를 효과적으로 통합
- 외부 감각의 신뢰도를 학습하여 동적으로 조절
- 외부 감각이 부정확할 때는 고유 감각을 더 많이 활용하도록 학습
- RNN(GRU) 기반으로 Belif state를 추정하여 POMDP 문제 해결
- 게이트 디코더를 활용하여 Belif state의 유효성을 보장Gated Encoder
- 게이트 RNN 모델과 Multi-Modal Information Fusion 기법에서 영감
- adaptive gating 메커니즘 사용 → 외부 감각 정보를 얼마나 반영할지 조절
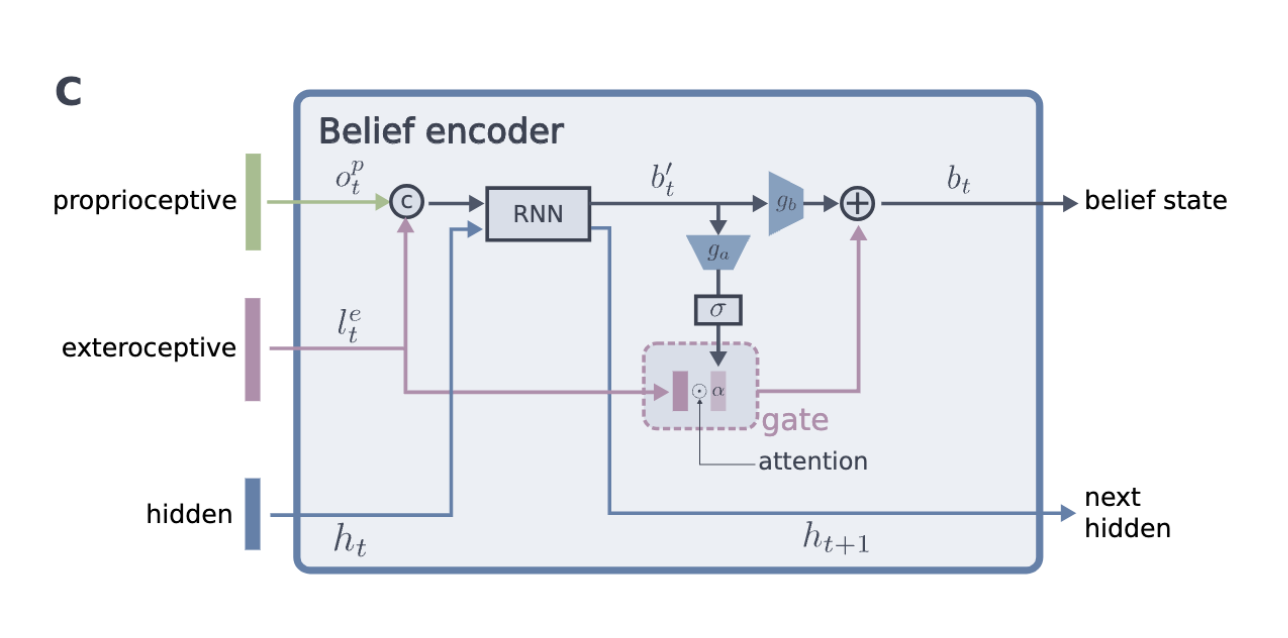
Belif state 계산 과정
- 입력 데이터
- 고유 감각: \(o^p_t\)
- 노이즈가 포함된 외부 감각 특징: \(l^e_t = g_e(\tilde{o}^e_t)\)
- 이전 숨겨진 상태: \(h_t\)
- 고유 감각: \(o^p_t\)
- RNN을 통해 중간 Belif state \(b^\text{'}_t\) 계산
\[ b^\text{'}_t, h_{t+1} = \text{RNN}(o^p_t, l^e_t, h_t) \]- GRU(Gated Recurrent Unit) 기반 RNN 사용
- 시간적 정보(Sequential Information) 유지
- GRU(Gated Recurrent Unit) 기반 RNN 사용
- attention 벡터 \(\alpha\) 계산: 외부 감각 정보를 얼마나 반영할지 결정 \[
\alpha = \sigma(g_a(b^\text{'}_t))
\]
- \(g_a\): 완전 연결 신경망(FCN)
- \(\sigma(\cdot)\): 시그모이드 활성화 함수
- \(\alpha\) 값이 클수록 외부 감각 정보를 더 많이 반영
- 최종 Belif state \(b_t\) 계산
\[ b_t = g_b(b^\text{'}_t) + l^e_t \cdot \alpha \]- \(g_b\): 완전 연결 신경망(FCN)
- 외부 감각 정보 \(l^e_t\) 를 attention 벡터 \(\alpha\) 에 의해 가중 조합
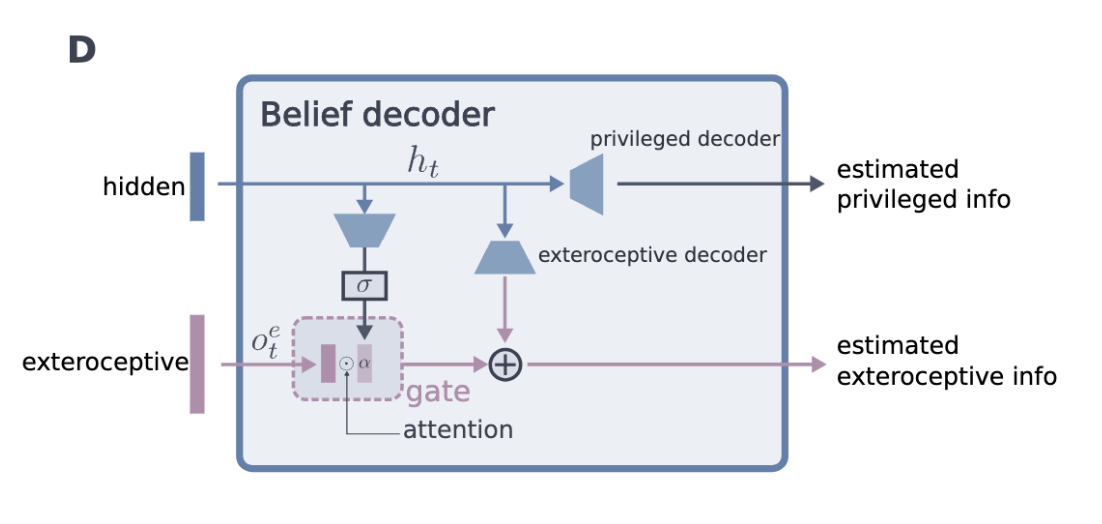
Gated Decoder
- 같은 게이트 메커니즘을 디코더에서도 사용
- Privileged Information 및 높이 샘플을 재구성
- Reconstruction Loss 계산 → Belif state \(b_t\) 가 환경 정보를 올바르게 반영하도록 유도
GRU(Gated Recurrent Unit) 사용 이유
- GRU는 LSTM보다 계산량이 적으면서도 장기 의존성(Long-term dependencies)을 효과적으로 유지
- 게이트 구조를 통해 중요한 정보만 선택적으로 저장 및 업데이트 가능